THDL++ tutorial - advanced templates
| <<Previous |
Overview
This chapter of the tutorial describes the most hardcore and the most time-saving features of THDL++ language. Those include:
-
Entities as template arguments
-
Functions and types as template arguments
-
Policy classes
-
Compile-time lists of policy classes
Entities as template arguments
The sad limitation of VHDL generics is that they can only define integral constants. If you followed this tutorial from the very beginning, you have noticed that we have provided the simulated clock in our examples by copy-pasting the ClockTest entity and changing the name of the inner entity instantiated inside ClockTest. THDL++ offers an elegant way to reuse such code instead of copy-pasting. Let's see an example:
{
signal logic clk = '0';
TestedEntity uut(clk = clk);
process clock()
{
clk = '0';
wait(Period / 2);
clk = '1';
wait(Period / 2);
}
}
Now, to simulate a 1 MHz clock connected to the 'clk' input of your arbitrary entity, you don't have to copy-paste anything. Just type:
That's it. Similarly you could instantiate the entity inside another entity:
Functions and types as template arguments
Let's consider a typical VHDL task: designing of a parallel combinatory min/max unit with a logarithmic depth. E.g., the unit that has 32 integral inputs, 8 bits each should return the minimal value and the index of the minimal value. Moreover, it should do it with a delay of O(log2(32)=5). The recursive implementation will look in the following way (using VisualHDL design visualizer):
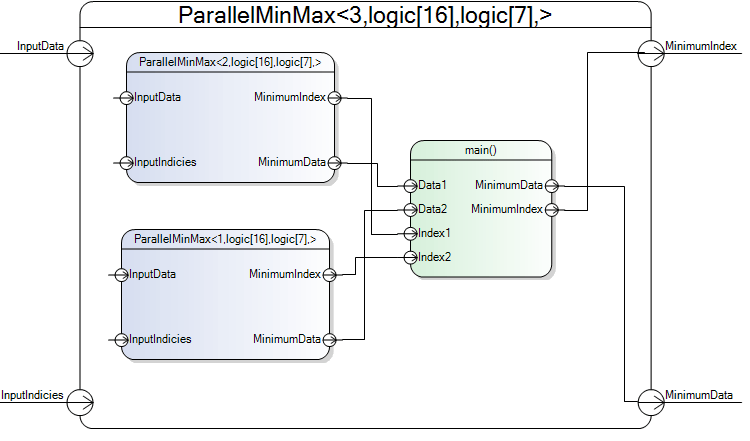
As you can see from the picture, a parallel min/max unit with 3 inputs internally contains a dummy unit with 1 input and a unit with 2 inputs. A unit for 6 inputs would contain 2 units with 3 inputs each and so on. That way, the combinatorial depth would grow logarithmically. In VHDL it is possible to create such design, but it will be fixed w.r.t. the type of each input and the operation (min/max). THDL++ allows creating a generic parallel comparison unit for arbitrary binary predicate, arbitrary data type and arbitrary amount of inputs. Let's have a look at the code (this sample is included in VisualHDL distribution; just select File->New Project->Sample Project):
template <any _Ty> bool Greater(_Ty left, _Ty right) { return left gt right; }
template <int _InputCount, any _DataType, any _IndexType, any _Predicate> entity ParallelMinMax
{
typedef _IndexType IndexType;
typedef _DataType DataType;
port
{
in DataType[_InputCount] InputData;
in IndexType[_InputCount] InputIndicies;
out IndexType MinimumIndex;
out DataType MinimumData;
}
signal IndexType Index1, Index2;
signal DataType Data1, Data2;
generate nested_modules if (_InputCount gt 2)
{
ParallelMinMax<_InputCount - (_InputCount / 2), DataType, IndexType, _Predicate> nested_pmin1 (
InputData = InputData[_InputCount - 1 to _InputCount / 2],
InputIndicies = InputIndicies[_InputCount - 1 to _InputCount / 2],
MinimumIndex = Index1,
MinimumData = Data1);
ParallelMinMax<_InputCount / 2, DataType, IndexType, _Predicate> nested_pmin2 (
InputData = InputData[_InputCount / 2 - 1 to 0],
InputIndicies = InputIndicies[_InputCount / 2 - 1 to 0],
MinimumIndex = Index2,
MinimumData = Data2);
}
else if (_InputCount == 2)
{
Data1 <= InputData[0];
Data2 <= InputData[1];
Index1 <= InputIndicies[0];
Index2 <= InputIndicies[1];
}
generate processes if (_InputCount == 1)
{
MinimumData <= InputData[0];
MinimumIndex <= InputIndicies[0];
}
else
{
process main(Data1, Data2, Index1, Index2)
{
if (_Predicate<typeof(Data1)>(Data1, Data2))
{
MinimumData = Data1;
MinimumIndex = Index1;
}
else
{
MinimumData = Data2;
MinimumIndex = Index2;
}
}
}
}
Now we can instantiate a "parallel min" unit for 16 elements each being logic[8] and each index being logic[3] by using the following entity name:
You could also use Greater instead of Less, or any other binary predicate function without changing (and thus re-testing) the ParallelMinMax entity implementation. That way we have completely separated the structural view (logarithmic recursive unit) from the functional view (min/max) and the implementation details (inputs widths/counts).
Policy classes
In the previous example we had a templated entity with 3 arguments. Having even more would make instantiating such entity quite a hassle. Fortunately, THDL++ offers a smooth way of fixing it. Let's add the following code to our example:
{
typedef logic[8] DataType;
typedef logic[3] IndexType;
const int InputCount = 16;
template <any _Ty> bool Predicate(_Ty left, _Ty right) { return left lt right; }
}
Now we can change the declaration of ParallelMinMax:
{
typedef _PolicyClass.IndexType IndexType;
typedef _PolicyClass.DataType DataType;
//Update _InputCount and _Predicate similarily
}
Now instead of ParallelMinMax<16, logic[8], logic[3], Less> we can just use ParallelMinMax<MyParallelMinPolicy>. By grouping lots of settings into policy classes code flexibility and reusability can be improved greatly. But even this is not the end! By inheriting the policy classes and redefine some of their members you can make your design even more flexible:
{
template <any _Ty> bool Predicate(_Ty left, _Ty right) { return abs(left) lt abs(right); }
}
You do not have to redefine InputCount and Data/Index types, you simply derive a new policy class based on an existing one and change the members you want to be changed.
Compile-time lists of policy classes
This feature is the combination of the ones presented above. Assume you are developing a CPU having a very non-uniform instruction set. You want to implement an instruction decoder unit having the following constraints:
-
You want to be able to enable/disable certain instruction subsets. For example, for some applications you want to build a very lightweight version of your CPU without advanced commands like push/pop.
-
Instructions have different formats. You don't want the code parsing a single instruction format to be scattered around a huge source file and intermixed with other code parsing other formats.
-
Some instructions have something in common. E.g. same location for "register A" field, but different ways of encoding the ALU opcode. You want to avoid copy-pasting for such commonalities.
One typical way to implement such decoder in VHDL would look like this:
opA = ...;
else if {this is instruction 2 or instruction 3} then
opA = ...;
else
...
end if;
if {this is instruction 1} then
opB = ...
...
end if;
The disadvantage of such approach is obvious: the code responsible for "instruction 1" is scattered around several it-then-else statements, that makes it hard to read, maintain and enable/disable for different builds. Another method would be:
opA = ...;
opB = ...;
else if {this is instruction 2} then
opA = ...;
opB = ...;
else
...
end if;
Here the code is less fragmented, but certain things common to "instruction 2" and "instruction 3" would have to be copy-pasted, again striking maintainability.
Is there a third option? In THDL++ there is! Let's describe our instructions using a hierarchy of policy classes:
{
bool Match(InstructionWordType insn) {...};
OpAType GetOpA(InstructionWordType insn) {...};
}
...
If a group of instructions shares some properties, simply derive them all from a common superclass, that's it! The instruction decoder implementation would look like this:
...
foreach (any insn in SupportedInstructions)
{
if (insn.Match(word))
{
opA = insn.GetOpA(word);
opB = insn.GetOpA(word);
...
}
}
Similarly to the parallel min/max unit we have separated the instruction definition (policy classes) from the instruction decoder internals (signals and the process containing foreach statement). Moreover, we have prevented the copy-pasting by using policy class inheritance.
What next?
Using policy classes to decouple orthogonal concepts of your design can be very powerful. And modern optimizers included in every VHDL compiling tools will ensure that your design efficiency won't suffer from that. To get more impression about THDL++ and its hardcore features, you can check out the OpenAVR project - an open-source fully AVR-compatible processor developed in THDL++.
| <<Previous |